rainflow 라이브러리의 최종 함수인 count_cycles는 extract_cycles에서 모든 사이클 데이터를 받아온 후,
각 range별로 최종 사이클을 카운팅해준다.
이때 사용자는 ndigits , nbins, binsize 세 가지 옵션 중 하나를 사용하여 원하는 형태의 사이클 카운팅을 할 수 있다.(반드시 하나의 옵션만을 사용해야 한다)
전체 코드
def count_cycles(series, ndigits=None, nbins=None, binsize=None):
if sum(value is not None for value in (ndigits, nbins, binsize)) > 1:
raise ValueError(
"Arguments ndigits, nbins and binsize are mutually exclusive"
)
counts = defaultdict(float)
cycles = (
(rng, count,i_start,i_end)
for rng, mean, count, i_start, i_end in extract_cycles(series)
)
if nbins is not None:
binsize = (max(series) - min(series)) / nbins
if binsize is not None:
nmax = 0
for rng, count in cycles:
quotient = rng / binsize
n = int(math.ceil(quotient))
if nbins and n > nbins:
if (quotient % 1) > 1e-6: # 최대한 정수에 가깝게 떨어지게
raise Exception("Unexpected error")
n = n - 1
counts[n * binsize] += count
nmax = max(n, nmax)
for i in range(1, nmax):
counts.setdefault(i * binsize, 0.0)
elif ndigits is not None:
round_ = _get_round_function(ndigits)
for rng, count in cycles:
counts[round_(rng)] += count
else:
for rng, count in cycles:
counts[rng] += count
return sorted(counts.items())결과
(range, count)의 형태로 반환된다.
default
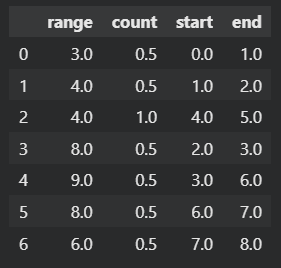
보기 쉽게 결과값을 데이터프레임 형태로 나타냈다.

아래는 extract_cycles 함수의 결과이다. 위의 최종 형태와 비교해서 보면, 중복되는 range 에 대해서는 cycle이 count 된 것을 볼 수 있다.
옵션1 : ndigits
range 범위의 형태 지정
# ndigits 적용
print(f'default return \n >> {rainflow.count_cycles(load_dt)}\n')
print(f'ndigits = -1 \n >> {rainflow.count_cycles(load_dt,ndigits=-1)}\n')
print(f'ndigits = 0 \n >> {rainflow.count_cycles(load_dt,ndigits=0)}\n')
print(f'ndigits = 1 \n >> {rainflow.count_cycles(load_dt,ndigits=1)}\n')
사용한 데이터가 소숫점이 없는 데이터라 큰 차이가 없지만, 음수로 입력할 경우, 10, 100, 1000 와 같이 range 범위를 크게 키울 수 있다.
옵션2 : nbins
구간의 수 지정 ( = range 수 )
# nbins 적용
print(f'default return \n >> {rainflow.count_cycles(load_dt)}\n')
print(f'nbins = 1 \n >> {rainflow.count_cycles(load_dt,nbins=1)}\n')
print(f'nbins = 3 \n >> {rainflow.count_cycles(load_dt,nbins=3)}\n')
print(f'nbins = 5 \n >> {rainflow.count_cycles(load_dt,nbins=5)}\n')
nbins=1 은 데이터에 존재하는 range가 한 개라는 의미로, 즉 데이터의 최댓값과 최솟값의 범위가 된다.
다시말해, 해당 range안에 포함되는 사이클의 수를 counting 하는 것이다.
옵션3 : binsize
구간(bin)의 크기 ( = range의 크기)
nbins를 입력하면 binsize가 자동으로 계산이 된다.
# binsize 적용
print(f'default return \n >> {rainflow.count_cycles(load_dt)}\n')
print(f'binsize = 1 \n >> {rainflow.count_cycles(load_dt,binsize=1)}\n')
print(f'binsize = 3 \n >> {rainflow.count_cycles(load_dt,nbins=3)}\n')
print(f'binsize = 5 \n >> {rainflow.count_cycles(load_dt,binsize=5)}\n')
print(f'binsize = 9 \n >> {rainflow.count_cycles(load_dt,binsize=9)}\n')
nbins와 연관성이 있는 것을 확인할 수 있다.
'🏷️Workplace > ANALYSIS' 카테고리의 다른 글
| [RainflowCounting] 라이브러리 분석 - 개요 (0) | 2023.10.17 |
|---|---|
| [RainflowCounting] extract_cycles( ) (0) | 2023.10.17 |
| [RainflowCounting] reversals( ) (0) | 2023.10.17 |
| 네이버금융 기업 실적 분석 데이터 크롤링 (2) | 2023.02.04 |
| [크롤링&SQL] 할리스 매장 정보 크롤링 후 DB 저장 (0) | 2023.01.24 |